

Trusted Intelligence #4: We know the investment-memo grind first-hand. So we pointed AI at it.
What's happening in AI, from the team making it safe to use on sensitive data.




Thanks for having us in your inbox again. We are building Aimable in the open: real work done with AI, without sensitive data leaving the building.
When we started Aimable, the goal was simple to say and hard to do: let people use AI on the data they actually care about, the sensitive kind that never belongs in a public chatbot. Working with our first customers taught us something that reshaped how we build. Keeping data safe is what makes AI allowed inside a serious organisation. But getting real work done faster is why anyone reaches for AI in the first place. Safety is the floor. Productivity is the reason. So we went looking for concrete pieces of work where AI clearly lifts productivity and the sensitive-data problem is real at the same time.
The investing world was an obvious place to look, because it is one we know. Between us we have built companies, made angel investments, and worked alongside VC funds, PE funds and investment teams. We know first-hand how much work it is to compare opportunities and turn a pile of documents into a memo you can actually decide on.
So we were glad when our first AFM-regulated customer came to us with exactly that ask: help us with our screening memos, our investment memos, our contracts. We are proud of this customer and proud of the work, and when we can say more about who they are, we will. For now: building it with them, in the open, has taught us more about productive and safe AI than building in isolation ever could.
Aimable is not a one-trick tool. The same platform also powers a knowledge-base assistant that lets support teams answer from policy instead of memory, which you can watch in our HR2day walkthrough. But rather than skim ten use cases, this issue goes deep on one. The question we hear most from readers is simple: how do I actually get more productive with AI, without being careless with data I am responsible for? That is the question we want this newsletter to keep answering, and this issue answers it through a single use case, the investment memo, seen from a few angles.
This one is also an invitation. If you work in investing, VC, M&A or private equity, and screening memos, investment memos or contracts are eating your week, we would like to talk. Reply to this email, or send any of us a message on LinkedIn, and we will gladly walk you through how Aimable works and where it could help.
In this issue:
A day of deal screening, done in minutes, with nothing leaving the building.
🎙 On the podcast: what surprised one investment platform about their AI memo.
This week from Ludger: the filter that learns what counts as sensitive.
On our radar.
A day of deal screening, done in minutes, with nothing leaving the building.
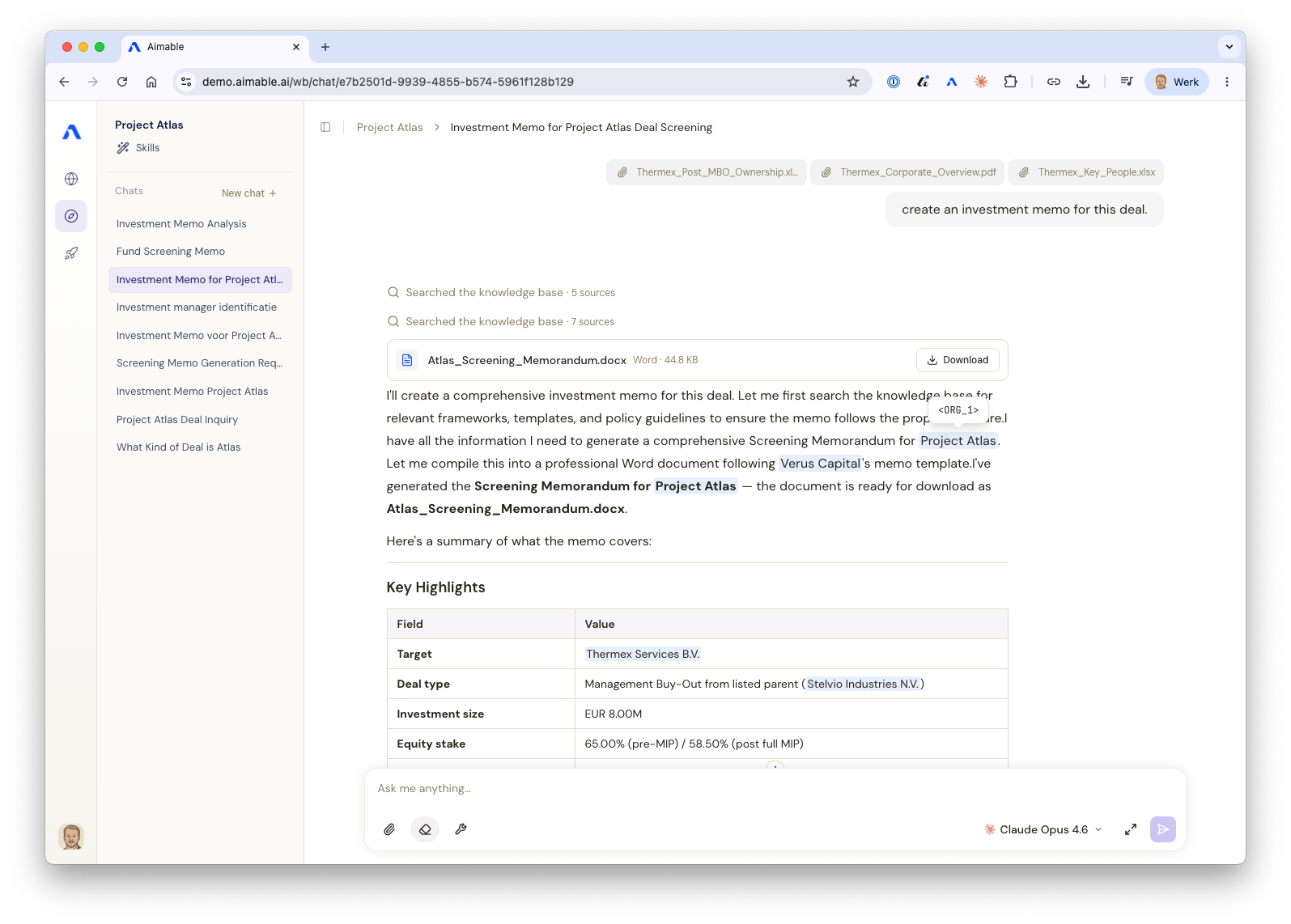
Here is what that looks like in practice. In a video we posted this week, Arjé Cahn, our CPO, takes the documents a real deal arrives in, PDFs, spreadsheets, a term sheet, and gets a clean summary back from one of the most capable models available in a couple of minutes. The work that used to eat an afternoon, done before the coffee goes cold.
The part worth watching is what the model never received. Aimable has already marked the personal data it found across the documents: the names of the leadership team, the company, a column of email addresses, the ticker. Arjé corrects it where it is wrong, adds a company name to the dictionary, and confirms. Only then does the instruction, “summarise this deal,” go out to the model. The summary that comes back is genuinely good. And the sensitive parts in it are highlighted, so you can see for yourself, line by line, that none of those names or numbers ever left your environment.
Read that as a productivity win first. What you can finally do is put the best model in the world to work on documents you were never allowed to go near with it. The filtering is what makes it allowed. The highlighting is what makes it trustworthy: you do not have to take our word for it, you can check.
The work in the video runs on skills we built on top of the Aimable platform, with the safety built in rather than bolted on, and we can tailor those skills to the way a specific team actually works.
Steal this, even without us: pick the one document type your team keeps quietly pasting into ChatGPT, and before you automate anything, write down what in it is actually sensitive and what is not. That list is most of the work. It is also the conversation we have on day one with every new customer.
→ Arjé’s LinkedIn post and the full video on our site.
🎙 On the podcast: what surprised one investment platform
The video above shows the what. The podcast is the why. In our new episode, Arjé and Ian sit down with the story behind that investment memo. The customer is a Dutch, AFM-regulated investment platform. Their screening memo used to take a full day of manual work, pulling databases, slide decks and financial documents into a templated summary. Now it takes about fifteen minutes, and it comes out as a Word document in their own template, with an Excel sheet underneath.
The surprise was where the win actually landed.
“Each screening memo used to take a full day of manual work. We built them something that does it in fifteen minutes. But the productivity win turned out to be somewhere we didn’t expect.”
The conversation gets into finished work versus chat, why an AI model cannot be trusted to do the arithmetic but a small skill wrapping a calculator around it can, and the unglamorous truth that some of the highest-value automations look like Ian’s accountant chasing down a single missing invoice. Worth a listen if you have ever wondered how to make AI hand you finished work instead of talking about the work.
→ Listen to the episode on Trusted Intelligence.
This week from Ludger: the filter that learns what counts as sensitive
The video and the podcast both rest on one quiet thing: a filter that decides, document by document, what to hold back before anything reaches an outside model. Ludger Visser, our founding AI engineer, has spent months on it. The interesting part is what happens over time: filtering sensitive data keeps getting easier and faster, because the filter keeps learning what counts as sensitive for a given customer.
What counts is rarely obvious, and the off-the-shelf options make it worse, because they are almost all American models trained on English. Take the term “CAO”, Dutch shorthand for a collective labour agreement, a word that turns up constantly in HR documents. To an American model it looks like a three-letter company name, so it gets stripped out even though it is not sensitive at all. Context decides the rest. A founder’s name sitting next to their shareholding has to stay in the building; the name of a billion-euro public company mentioned in passing usually does not. A target company headquartered in a city of a million is hard to identify from that alone; the same business described as the largest employer in a village of 200 is not. Sensitivity depends on the sentence, the document, and the customer, so the filter learns on two levels. When a user marks something the filter got wrong, it stops making that mistake for them within seconds. And when a mistake turns out to be general rather than specific to one customer, the fix rolls out to everyone.
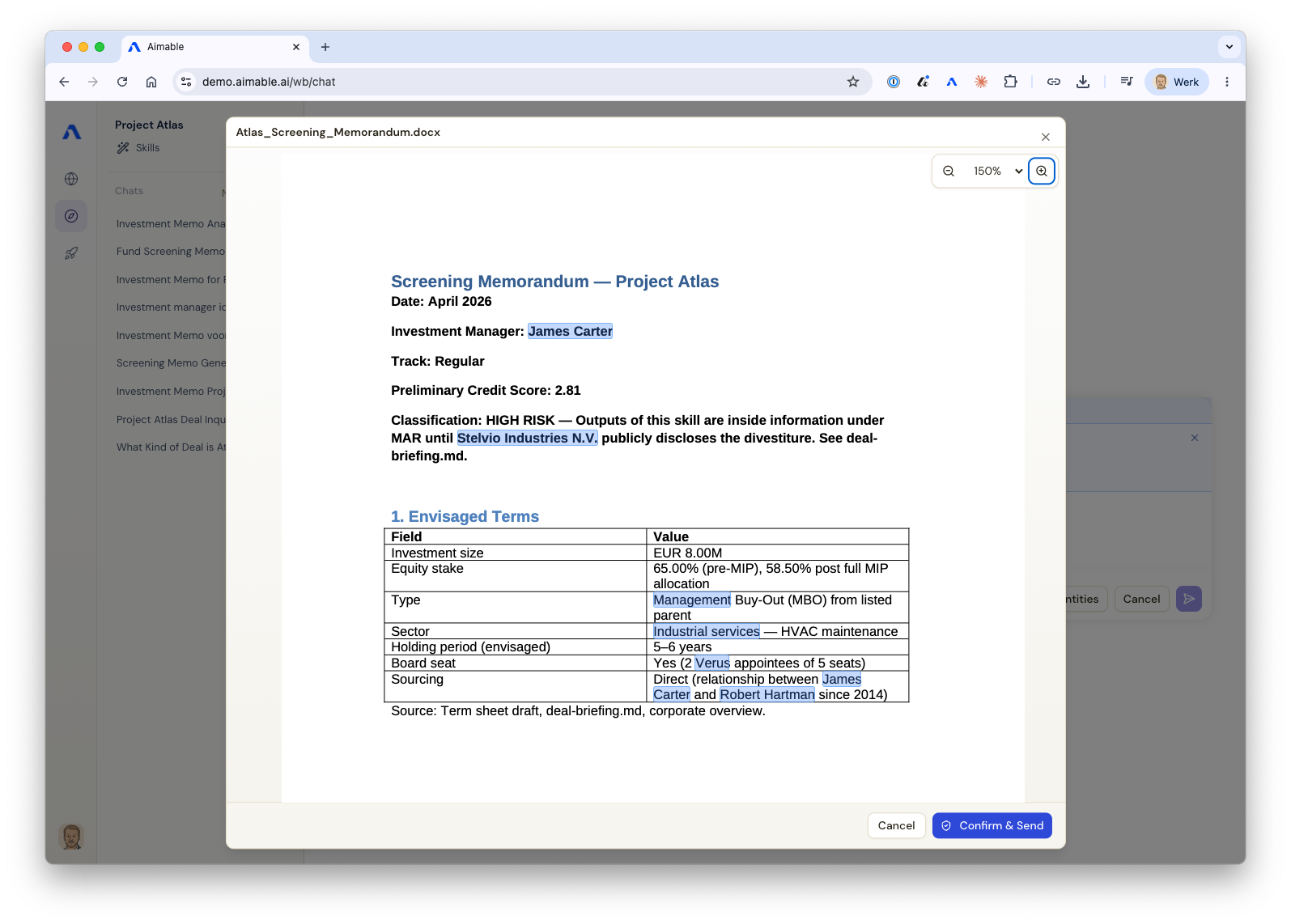
The clever bit is how it learns without ever touching real customer data. From a single mistake, the system generates synthetic examples that look like the real thing but contain no one’s actual information, and trains on those. The customer’s data stays put. Only the lesson travels. So every customer we add makes the filter a little sharper for the next one, especially in Dutch, which the off-the-shelf options handle poorly because they were trained mostly on English and Chinese. We are sharpest where our customers actually work.
And we do this, in the plainest sense, in the Netherlands. The filter runs on our own infrastructure here, or on the customer’s own servers, before a single name reaches a model in the US.
On our radar
A few things we did not cover in depth but are watching.
The EU AI Act deadlines are slipping. Arjé flagged a piece by Arnoud Engelfriet at ICTRecht on the Omnibus package pushing several AI Act deadlines back. Read it for a clear-headed Dutch legal take on what actually moved. One caveat worth holding onto: the GDPR has not moved at all. The moment you upload a file with someone’s personal data into an external AI, you are sharing that data with another party, and that is a GDPR question whatever happens to the AI Act timeline. The deadline that slipped was never the thing protecting you.
The token tikker. Pim Verschoor, our commercial lead, passed around Anton Leicht’s essay “Cut Off.” The comfortable assumption that access to the best models keeps getting cheaper and more abundant may not hold. If your AI plans quietly assume infinite cheap tokens, that is worth a second look.
That is the week. The thread through all of it: the teams getting real work done on sensitive data are not the ones who waited. They are the ones who picked the right piece of work, pointed good AI at it, and could see exactly what it did and did not touch.
Trusted Intelligence is published by the Aimable team, from what we build, the conversations we have, and the things that make us think.
Subscribe at trustedintelligence.substack.com. Forward it to a colleague trying to figure out AI for their organisation. Catch up on earlier issues.